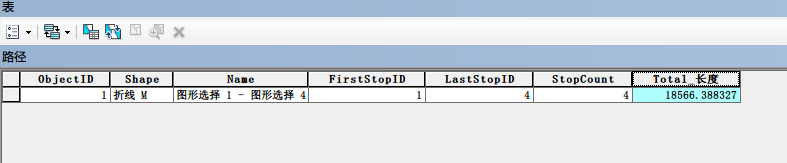
update: 修改了代码,现在可以实时检测电脑是否在线
Wake-on-LAN简称WOL或WoL,中文多译为“网络唤醒”、“远程唤醒”技术。WOL是一种技术,同时也是该技术的规范标准,它的功效在于让休眠状态或关机状态的电脑,透过局域网的另一台电脑对其发令,使其唤醒、恢复成运作状态,或从关机状态转成引导状态。
对于支持网络唤醒的主机,我们可以使用路由器的网络唤醒功能来开机。但是网络唤醒需要的是网卡和主板的支持,还需要你有公网ip或者路由器支持远程唤醒,任何一项不支持都不能正常启动。而且即使支持了网络唤醒,万一遇到了意外断电,有的主板也不能正常开机。那么有什么办法能保证网络唤醒一定成功呢?
最简单的方法是智能插座,在BIOS里设置好主板通电就开机,然后远程控制智能插座就可以了。这种方法最简单,但是笔记本是有电池的,所以BIOS里一般没有通电开机的选项,这个办法就行不通了。
准备
那么怎么办呢,首先我们来了解一下电脑的启动流程:
开机按键一端和电源14脚或16脚相接,另一端接地,当我们按下电源按钮时,电源的14或16脚接地,然后就会触发电源开始工作,向设备供电。(这种说法只是为了方便理解,实际流程很复杂)
既然知道了这个原理,那我们只要让电源引脚接地,模拟开机键按下的过程,不就能开机了吗。
为了实现这个功能,需要以下材料:
- 一个esp8266,用于联网
- 一个esp8266 relay,用于短接电源引脚,
- 一个usb转ttl,同于给esp8266刷写程序
- 电烙铁,用于引出开机线路
- 一个万用表,用于测试
- esp8266开发软件,我用的是arduino IDE
硬件
首先需要的,当然是拆开电脑,找到对应的启动引脚了,台式机的话很简单,看电源按钮排线就行,笔记本的话,可以直接看电源按钮的线路,也可以找根线,一端接地,一端在电源按钮排线上一个一个短接试过去。
找到引脚后,就要想办法用电烙铁引过来地线和电源线,这里推荐用耳机线,很软很细不容易断,不会让设备外壳合不上。
然后把这两根线接到继电器的公共口和常闭口就行。
软件
接着就要写程序远程控制继电器开合。推荐使用点灯科技的blinkerSDK,配合手机app可以很方便的控制。blinker使用方法请自行搜索,
新建一个blinker设备,获得Secret Key,然后开始编程:
需要用到的库:ESP8266Ping,注意不是arduino仓库里的那个ESP8266-ping,这个要自己下载放到libraries文件夹里。
1 |
|
Blinker还可以支持小爱同学远程控制,不过我懒得写了,以后再补上
程序的刷写方法可以参考这里:https://www.diyhobi.com/flash-program-esp-01-using-usb-serial-adapter/
接法是这样的:
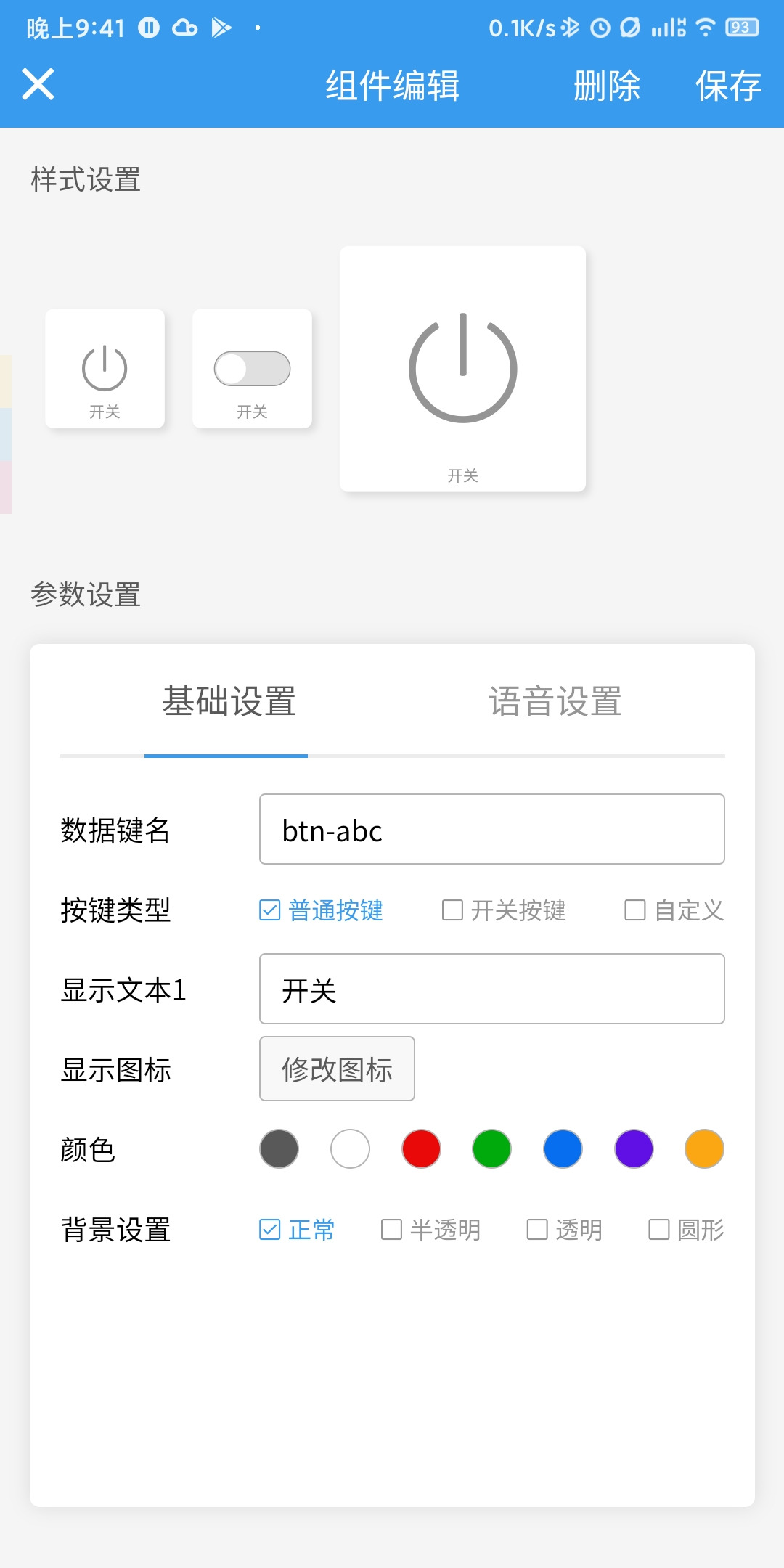
写好之后,在blinker app立面编辑界面,新增一个按钮,数据键名为btn-abc,类型为普通按键(现在可以选择开关按键,样式选择第二个滑块按钮可以看到机器开关状态)。然后就可以用了